Learn how to get more value from your data while simplifying the deployment and management of analytic initiatives—all with HPE BlueData EPIC software and SQL Server Big Data Clusters.
This post has been originally published for on HPE Blogs.
BlueData EPIC software from HPE and SQL Server Big Data Clusters (BDC) from Microsoft can help you transform data siloes into a unified data lake—so you get more value from your data while simplifying the deployment and management of analytic initiatives.
It may seem paradoxical but despite the increase of tools and technologies to manage big data, advanced analytics, and AI models, most parts of many companies still struggle to launch successful analytics programs. As companies make the digital transformations, they grind away at the basics like figuring out how to extract useful insight from their data and how to evolve into data-driven cultures.
Several reasons explain why this transition is hard:
- Hybrid edge-to-core-to-cloud and multi-clouds strategies require IT architectures that support portable applications that can easily be deployed and moved to/from edge, core and clouds.
- Big data analytics, artificial intelligence (AI) and machine learning (ML) workloads require flexible and specialized hardware systems like GPUs, high density memory, and scale-out storage to address the data volumes and complex analytics across these workloads.
- Data democracy requires a mindset change as companies move to open and seamless data access, move from monolitch apps to the freedom to use a variety of open source analytic tools, and self-service deployment of analytics environments and sandboxes to allow data exploration and AI/ML
To address these problems, IT organizations needs analytic platforms capable of:
- Virtualized infrastructure that separates compute from storage so infrastructure can be software defined to meet your workload requirements.
- On-demand resource allocation so apps can be quickly spun up or down and easily ported applications from/to across hybrid environments.
- Self-service access to data and applications so that IT doesn’t impact the productivity of the data science communities.
Let’s see how these architectures can be realized using the combination of BlueData and SQL Server BDC.
Virtualize and integrate data and separate it from the infrastructure
Data virtualization and integration: Most enterprises have data stored in various databases such as Oracle, MongoDB, Teradata, or PostgreSQL, for example. To use this data, applications must access data from these various data sources and combine it into a single source. Moving or copying the data around the different sources is a challenging effort.
SQL Server 2019 provides a data virtualization solution, using the PolyBase feature, to improve ETL and data integration processes. Polybase data virtualization capabilities allows integrating data from different sources such as MongoDB, Oracle, DB2, Cosmos, and Hadoop Distributed File System (HDFS) without data movement or replication. This allows the creation of a unified virtual data layer that can support multiple applications. PolyBase can push as much of the query as possible to the source system, which optimizes the query performance.

Figure 1. Data virtualization with SQL 2019 BDC Polybase
Compute and storage separation: The traditional Hadoop architecture was founded upon co-location of compute and storage within the same physical server as the only way to get good performance with large-scale distributed data processing as network performance was the bottleneck. The side effect of this was that compute and storage could not be scaled independently and that data can’t be shared across multiple Hadoop cluster.
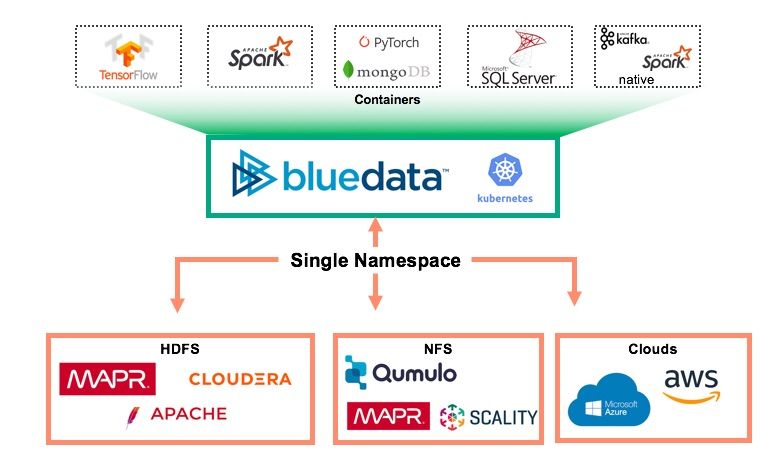
BlueData’s DataTap component disconnects analytical processing from data storage, giving you the ability to independently scale compute and storage on an as-needed basis. With BlueData, you also have unparalleled flexibility to mix and match infrastructure. You can run the BlueData platform on-premises, on multiple public clouds (Amazon Web Services, Google Cloud Platform, or Microsoft Azure), or in a hybrid model. This enables more effective utilization of resources (e.g. less hardware) and lower operating costs.
Another benefit of DataTap is that you can access data from any shared storage system (including HDFS as well as NFS) or cloud storage (e.g. Amazon S3). Indeed, Datatap allows the creation of a single data access point (single name space. This means that users can centralized access to all the files whether the data is on-premises, in the cloud, or on the edge. Moreover, BlueData allows the expansion to the single name space concept across multiple different storage solutions. The single name space can be extended across QSFS, HDFS (multiple version and distributions), NFS storages, and Cloud.
Allocate hardware resources on-demand to applications, quickly spin-up and easily move them from/to different environments
Easy application deployment: BlueData allows users to on-demand provision new containerized environments with just a few mouse-click. This allows data scientists and analysts to have a cloud like experience by being able to self-service data analytic clusters within minutes, while accessing centralized and shared data.
Moreover, SQL Server BDC allows organizations to create, manage and control clusters of SQL Server instances that co-exist in a cluster of containers with Apache Spark and AI/ML and Hadoop environments. This allows to use standard SQL language to access and process large sets of data stored into the data lakes.
BlueData and SQL Server BDC both support the industry-standard Docker containers making it easy to port applications across the expanded distributed landscape.
Security and multi-tenancy: Different project teams, groups, or departments across the enterprise can share the same infrastructure—and access the same data sources—for AI/ML and Big Data analytics workloads. BlueData provides multi‑tenancy and data isolation to ensure logical separation between each project, group, or department within the organization. The platform integrates with enterprise security and authentication mechanisms such as LDAP, Active Director, and Kerberos.
AI and Machine Learning operationalization: BlueData provides a full lifecycle platform to build, train, deploy and monitor machine learning solutions. It is a multi-user, collaborative environment with Git version control and file system integration with model and project repositories built in. BlueData provides a full AI/ML lifecycle operationalize solution capable to accelerates the rollout of full production environment machine learning solutions from months to just days with the HPE ML Ops add-on.
On-demand, elastic provisioning of infrastructure: BlueData’s enterprise container offering delivers stateful containerized environments can be easily provisioned on-demand and then deprovisioned when no longer needed. For example, GPU resources from multiple GPU-enabled servers can be pooled and shared across multiple project teams. IT admins can provision right-sized environments per the end-user’s requirements, ensuring that each workload is allocated the number of GPUs it needs.

Figure 3. BlueData resources utilization dashboard
Self-service environments with flexibility for tools of choice: BlueData leverages the power of Docker to allow data science teams to create their own containerized environments—accessing data in on-premises or cloud-based storage on-demand within minutes. Fully configured applications are automatically provisioned with just a few mouse clicks, whether they’re transient for development and testing, or long-running for a production workload.
BlueData includes an “App Store” for common AI/ML and Big Data Analytics applications, distributed computing frameworks, and data science tools. Additionally, add your own preferred toolkits or containerized apps like NGC from NVIDIA to quickly upgrade to new versions while providing the ultimate in agility and configurability. SQL Server instances, with their data, can also be spun-up as containers, allowing data analysts to query and manipulate large data sets.
Get ready to get more value from your data
In conclusion, the combination of the HPE BlueData EPIC software and SQL Server BDC allows organizations to create a sophisticated next generation big data analytics architecture capable of satisfying all the enterprise needs for launching and managing successful analytics programs.
Watch for more info: